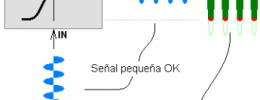
Síntesis (16): haz cantar a tu sinte (filtros de formantes)
La aplicación de un filtro pensado desde la electrónica pura a un uso musical no es necesariamente lo ideal. Un filtro paso bajo o paso banda tendrá sentido en sistemas de comunicación o para un robot, pero quizá no es lo más sensato musicalmente. ¿No podemos invertir las tornas? ¿No podemos estudiar qué es lo que da carácter a un sonido musical y crear un filtro que corresponda directamente a esa acción?
Bienvenidos a los filtros de formantes, cuyo diseño nace de estudiar el comportamiento del habla y de las resonancias naturales en los instrumentos.

Resonancias de los instrumentos
[Índice]Ya en la primera entrega de la serie hablábamos del fenómeno de las resonancias en el cuerpo de los instrumentos. La vibración original que acontece en el instrumento acústico (ya sea de la cuerda, de la lengüeta, de la columna de aire, de la barra metálica,…) no se genera en un espacio libre, vacío, abierto. Está obligada a suceder dentro del reducido espacio del cuerpo del instrumento que actúa (y así lo llamamos) como caja de resonancia.
Al igual que nuestra voz no suene igual dentro de una habitación u otra, porque se colorea con los rebotes y absorciones que se producen en ellas, el sonido inicial del elemento vibrante del instrumento se modifica, y mucho, al proyectarse en presencia del cuerpo. Pensad en la caja de un violín o una guitarra, por poner un caso fácil de entender.
El cuerpo del instrumento es una ‘minihabitación’. Dentro de él hay rebotes. Un buen número de ellos, y además muy cercanos en el tiempo (por las reducidas dimensiones). Impensable que oigamos esos rebotes como ‘ecos’, pues suceden en intervalos de tiempo tan próximos entre sí que nuestro oído es incapaz de separar su escucha. Oye un efecto de coloración, de realce/amortiguación de algunas frecuencias (al igual que un eco se convierte en un filtro peine si bajamos suficiente el tiempo de retardo). En función de los materiales y sus absorciones (siempre variables con la frecuencia) y de las dimensiones y forma del cuerpo, así saldrán reforzadas o rebajadas unas u otras regiones de frecuencia.
Pensad por ejemplo en un modelo demasiado simple e irreal: una caja rectangular de paredes paralelas. Entre cada dos paredes paralelas tenemos un camino de rebote persistente y regular. Tres direcciones principales (tres pares de paredes) y por tanto tres frecuencias que probablemente se verán reforzadas (realmente ellas y sus múltiplos). Hay determinadas frecuencias que ‘resuenan’ más fuertemente en ese cuerpo porque son favorecidas por los caminos de ‘rebote’ principales.
Cualquier cuerpo ‘tridimensional’ tiende a ofrecer múltiples frecuencias a las que ‘resuena’. En la caja rectangular identificamos con cierta facilidad esas tres distancias principales y sus correspondientes frecuencias. Pero en la caja del violín o la guitarra tiene una forma mucho más compleja y con ella un patrón igualmente rico de resonancias. De forma parecida sucedería con cualquier otro instrumento.
Y ¿qué tenemos en un sinte normalito? Un simple LPF, un filtro paso bajo. Mal modelo realmente para la complejidad de lo que estamos comentando. Jugando con el control de resonancia podemos enfatizar una gama de frecuencias, pero a cambio estaremos cortando todo lo que viene por encima. Con suerte podremos llegar a imitar la primera de esas resonancias, o la más prominente, pero perderemos el detalle de las restantes, que son igualmente necesarias para conformar el carácter final del sonido.
Necesitamos ser capaces de realzar simultáneamente varias ‘resonancias’, realzar (a la vez) varias regiones de frecuencias en el espectro de audio. Sólo así tendremos una razonable aproximación a la realidad de los instrumentos acústicos.
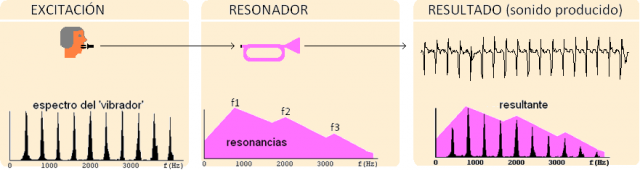
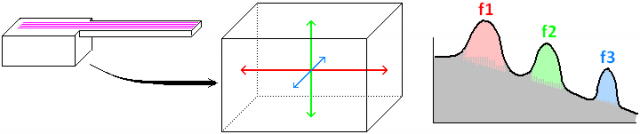
La figura proviene de analizar un sonido real de trompeta. Veis cómo es el espectro del sonido irritante que produce la boquilla desacoplada del cuerpo. Veis cómo sería el ‘filtrado’ que realiza el cuerpo (esa caja de resonancia que absorbe/realza selectivamente unas frecuencias más que otras). Y veis el sonido grabado y su espectro, tal como estamos acostumbrados a oír la trompeta.
Aunque es cierto que en el resultado final hay un carácter general ‘paso bajo’ (más amplitud en armónicos graves que en agudos), no podemos dejar de apreciar que no es una caída monótona, sino que está acompañada de varios realces locales. Los he señalado con las indicaciones f1, f2, f3 (frecuencias 1, 2 y 3) en la figura de la acción del resonador.
En nuestro megasinte además de un LPF tendremos quizá un HPF, un BPF, un BRF, o con suerte contemos con un filtros ‘notch’, ‘comb’, ‘peak’, ‘shelve’,… Muchos nombres y tipos de filtros, pero todos muy artificiales. Ciertamente podríamos reunir un buen número de ‘peaking’ filters y usarlos para recrear las resonancias principales. Pero pocas veces tenemos a mano tantos filtros para usarlos simultáneamente.
El patrón de cuáles son esas frecuencias que se ven realzadas es el que nos permite distinguir o clasificar muchos sonidos. Estas resonancias suelen ser muy destacadas, muy intensas. En términos más técnicos, con un ‘Q’ muy elevado. Cada una de ellas actúa muy fuertemente (con muchos dBs de ganancia) en una región relativamente estrecha de frecuencias. Mirad como ejemplo esta nota de violín (conocida de otras entregas y que ahora revisamos bajo este nuevo prisma).
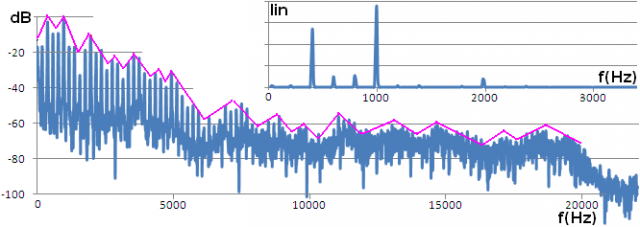
En el ejemplo las resonancias son tan marcadas sobre aprox. 400, 1000 y 2000 Hz que en una representación lineal de la amplitud ‘perdemos’ el detalle del resto del sonido. Sólo en una representación logarítmica (en dBs) logramos ver todo el detalle y comprobamos la existencia de un enorme número de realces locales.
Afortunadamente no es necesario atender finamente tanto detalle. Nos basta reproducir las resonancias principales. Pero mejor lo vemos ya presentado sobre el habla y los formantes.
Formantes del habla
[Índice]En el caso de los instrumentos musicales, el término que aplicamos para denominar a esas frecuencias enfatizadas es el de ‘resonancias’, mientras que en el habla se acostumbra a usar el término ‘formantes’. Pero se trata de una misma realidad: en los ‘productores acústicos’ que estamos acostumbrados a oír (la voz, los instrumentos) hay muchas zonas estrechas de frecuencia que son realzadas.
Pensad en las vocales: A, E, I, O, U. Claramente el sonido de la ‘A’ que produce un bebé, un niño, una niña, un hombre, una mujer, alguien acatarrado, … no es el mismo. Hay enormes diferencias y sin embargo no dudamos en clasificarlo como una ‘A’. Por tanto algo habrá en común dentro de toda esa infinidad de variantes de sonidos que sin embargo entendemos como propios de la ‘A’.
Y lo que tienen en común es, precisamente, las resonancias, o, en términos más propios de estudios sobre habla, los formantes.
El tracto vocal es extraordinariamente maleable. Es como si en la caja rectangular que antes pintábamos pudiéramos mover las paredes para formar diferentes volúmenes. Podemos configurar diferentes ‘formas’ de caja, de cuerpo de resonancia, y con ello conseguir la enorme variedad de sonidos que podemos realizar con la propia voz. Tenemos un sintetizador excelente, y que es además ‘acústico’ (ríase usted de lo analógico, la voz si que es el ‘sinte vintage’ por excelencia).
Hay muchas publicaciones que ofrecen los cuadros o tablas de formantes. Establecen qué frecuencias hay que enfatizar para conseguir un sonido tipo ‘A’, ‘E’, ‘I’, etc. El procedimiento para obtenerlas es simple. Se registra y analiza la voz de un alto número de personas y se observa y anota dónde se producen los realces. En la imagen de la señal se pueden identificar fácilmente los arranques de cada ‘pulso glotal’ (la apertura explosiva de la glotis, la vibración original en las cuerdas vocales, sumamente impulsiva). Sea cual sea la duración T0 entre impulsos (o su inversa, la frecuencia fundamental f0, que es la que define la ‘nota’ que oímos y la distancia que habrá entre los sucesivos armónicos) las frecuencias de resonancia (F1, F2, F3, F4, F5 en la figura) varían muy poco cante la nota que cante o hable un locutor u otro.
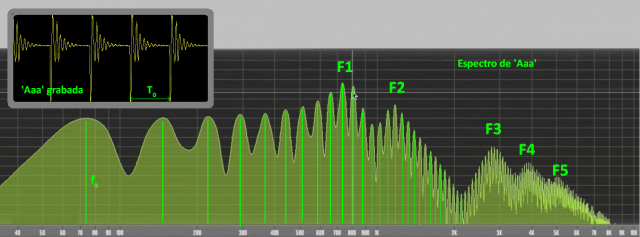
Se puede observar al reunir los resultados para un grupo de personas que los formantes se producen de forma aproximada en las mismas frecuencias para todos los locutores. En realidad esas tablas existen separadamente para cada idioma (en cada uno las vocales son diferentes en número y sonoridad). Aquí os ofrezco algunas tomadas de internet, y que como veis esencialmente coinciden.
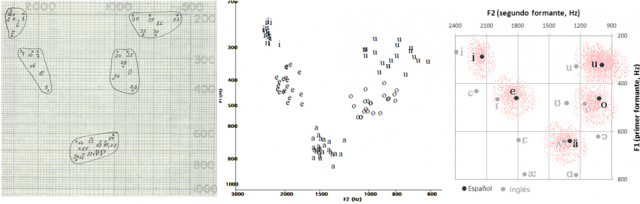
Si quisiéramos crear sonidos que emulen las vocales tendríamos que ser capaces de recrear esos formantes. En el caso del español, con sólo cinco vocales, puede haber una diferenciación, aunque algo pobre, aplicando sólo dos formantes. Pero la recomendación mínima suele exigir que se usen al menos tres formantes (los tres principales de cada vocal) para conseguir una percepción nítida y bien separada de las vocales. Esa es una recomendación que se aplica en el caso de sistemas telefónicos, limitados a 3KHz, y por tanto con voz muy filtrada.
Para sonidos algo más naturales, articulados y extensos en banda es preferible contar con la posibilidad de realzar un mayor número de regiones de frecuencia.
Los filtros de formantes
[Índice]Los sistemas telefónicos son los responsables de un buen número de tecnologías de las que disfrutamos en audio y en particular en síntesis. El nacimiento de los ‘vocoder’ (voice coder / decoder) tiene que ver con el intento de reducir la información necesaria para transmitir voz. Y dentro de todos esos desarrollos están también los filtros de formantes.
Se trata de filtros de una complejidad (en cuanto a su estructura interna) notablemente superior a los habituales LPF, HPF, etc. Están concebidos para poder realizar un patrón de realces selectivos sobre varias frecuencias. Hay distintas realizaciones. En algunos casos puede tratarse de varios filtros ‘peaking’ en paralelo. Cada uno de ellos capaz de enfatizar una gama de frecuencias (con una ganancia y un Q ajustable). En otros casos (sobre todo en modelos digitales) puede ser un filtro definido directamente en el dominio espectral. Pero más allá de la tecnología con la que se consiga el objetivo es el de imitar esos realces propios de la voz.
Sus controles (en lugar de corresponder a ‘frecuencias de corte’ individuales) suelen venir expresados mediante un ‘selector de vocal’ que ofrece como opciones ‘A’, ‘E’, ‘I’, etc. En muchos casos las trayectorias intermedias entre dos vocales son factibles y se realizan modificando (a la vez) las frecuencias y ganancias de los formantes (esas ‘montañas’ en la respuesta en frecuencia del filtro), para que exista un verdadero ‘morphing’, una evolución continua desde una vocal a otra, tal como sucedería en el habla (al articular una sucesión de vocales no movemos el tracto vocal ‘a saltos’ sino de forma contínua).
Un filtro de formantes que tenga un ‘selector de vocal’ está pensado sólo para recrear sonidos vocales, pero tiene la enorme comodidad de simplificar los controles. Luego os muestro un ejemplo en una demo. Imaginad la complejidad de controlar todo adecuadamente si montáis vuestro propio ‘filtro de formantes’ reuniendo 3 filtros ‘peaking’ (mejor aún alguno más). Cada vez que deseéis cambiar de vocal hay que retocar a la vez los parámetros de 3 filtros. No tenemos manos suficientes. Pero a cambio esa arquitectura con tres filtros libremente configurables os permitiría imitar otros sonidos no vocálicos (por ejemplo los de instrumentos acústicos) porque podríais ajustar a voluntad las frecuencias, ganancias, y Qs de cada filtro.
Al igual que con la síntesis basada en modelos aditivos podíamos conseguir realismo a costa de la complejidad de programación y control, esta vía de la recreación de las resonancias/formantes es muy exigente si la tenemos que montar desde la nada (sin el apoyo de filtros específicamente concebidos para usos concretos como estos de formantes para sintetizar vocales).
Un filtro de formantes dedicado (pensado específicamente para vocales) oculta esa complejidad ofreciendo el ‘selector de vocal’.
Demostración en vídeo
[Índice]Ilustraremos el artículo de hoy con la ayuda del filtro de formantes que incorpora el MiniV de Arturia. Por cierto: ni de broma penséis que vais a obtener estos sonidos con un MiniMoog tradicional. He usado fundamentalmente los muchísimos extras que Arturia implementó en su recreación del MiniMoog. Desde el carácter polifónico, a la presencia de efectos, la posibilidad de realizar rutas de modulación avanzadas, y , por supuesto, ese filtro de formantes (vocal filter) que nos permite ilustrar el tema de hoy.

Aquí tenéis un guión detallado de lo que veréis en el vídeo.
Parto primero de un sonido cuyo espectro es plano: el ruido blanco. Le aplico un filtro de formantes y os muestro cómo ese ruido blanco se matiza con sonoridades propias de A, E, I, O, U (es una U inglesa, intermedia entre nuestra O y U en español). Claramente las vocales se oyen y distinguen. En el propio vídeo, veréis cómo, al subir la resonancia (la selectividad) del filtro de formantes, el resultado se hace más cercano a voz, reduciendo poco a poco la presencia del ruido y haciendo dominante la sensación vocal.
Como además os muestro el espectro de lo que está sonando, podéis ver dónde están colocados los realces, los formantes, en cada vocal. Os llamo la atención sobre el hecho de que este filtro está usando 5 formantes. Es necesario porque el ancho de banda en el que trabaja es mucho mayor que los 3KHz telefónicos.
Eso sí, en la primera parte del vídeo, como la fuente inicial es ruido el sonido resulta equivalente al de cuando susurramos o al de alguien acatarrado que habla sin hacer vibrar las cuerdas vocales para que no le duela la garganta, limitándose a dejar salir el flujo de aire que se colorea al atravesar el tracto vocal.
Tras ello veréis lo que sucede al procesar la salida de un oscilador en lugar de usar ruido como fuente. Es ahí donde escuchamos ya un sonido vocal convencional (no susurros). Pero notaréis que mientras sean sonidos estáticos resultan todavía poco atractivos, excesivamente artificiales. Como siempre insisto, los sonidos realistas y orgánicos necesitan movimiento, articulación. La ‘A’ perfecta, estática, definida por la ‘media’ de los locutores, es tan artificial como lo es el sonido plano y sin movimiento de un oscilador. O como cuando el médico os pide ‘diga Ahh’. Es un sonido aburrido y muerto.
El movimiento es imprescindible. Por ello el siguiente ejemplo del vídeo realiza un recorrido cíclico por las cinco vocales controlando el filtro de formantes desde un LFO, y con ello se va obteniendo una sensación algo más realista. Se trata todavía de un movimiento demasiado regular, y por tanto rápidamente predecible, con lo que sigue oliendo a artificio. Pero notaréis que la ‘calidad’ empapada de movimiento asciende muchos grados.
Como esos ejemplo se basan en mantener pulsada una sola nota y nadie puede afinar tan bien (salvo usando ‘autotunes’ y semejantes) ni durante tanto tiempo, el realismo también se ve afectado por ello.
Conseguir un uso que suene ‘realista’ implica, como siempre, mucho trabajo en la parte de control, y concebir asimismo usos que tengan sentido musical. El vídeo continúa por ello con algunos pasos intermedios que van sumando puntos en el sentido de ofrecer, más que credibilidad (algo que personalmente no me interesa mucho) sí esa ‘actividad interna’ y ‘riqueza’ que esperamos de los sonidos acústicos, en este caso vocálicos.
Juego por supuesto en parte con efectos (chorus y delay que realcen la sensación de coral) pero también con parámetros de la síntesis (osciladores en octavas para simular las diferentes voces del coro, filtrado global paso bajo porque es propio de la voz humana,…) y con parámetros que musicalmente hagan funcionar al sonido obtenido. Es este último sentido, dado que el recorrido cíclico por las cinco vocales es demasiado predecible lo oculto a base de usar un LFO en diente sobre la amplitud para simular el redisparo de las notas (que no estén exponiéndose continuamente) mientras un LPF se va cerrando para impedir que todas esas notas redisparadas sean idénticas en color, etc. Y por supuesto, en vez de hacer sonar una única nota o acorde, voy realizando al final algún tipo de progresión que le dé sentido e interés musical.
Insisto: no pidáis realismo (no he estado haciendo una edición detallada, sólo toqueteando sobre la marcha con lo que tenía disponible a primera vista en este sinte) pero fijáos en cómo hemos ido construyendo un sonido y un uso cada vez más musical.
Pruébalo tú mismo
[Índice]He de reconocer que me lo he pasado bomba preparando este artículo (espero que os haya gustado). Si queréis probar con el mismo producto que he usado yo para el vídeo os recuerdo que podéis usar la demo de MiniV de Arturia para Mac o PC. Es de hecho lo que he usado yo. La demo de MiniV se corta al cabo de un tiempo y tiene tras muchas protecciones pero os permite usar y probar todo lo que hemos contado. Por eso me pareció buen producto para la demo: podéis también jugar con él como yo lo he hecho y pasar un buen rato (eso sí, no me pidáis cuentas de las consecuencias para vuestro bolsillo -el mío ya va muy malito con tantas tentaciones…-).
Por si queréis tomarlas como modelo cara a crear vocales en otros sintes aquí os dejo las frecuencias que usa el ‘vocal filter’ del Arturia Mini V para las distintas vocales (en Hz.). Son por supuesto valores aproximados y que admiten cierta holgura. En el Mini V se usan 5 formantes (presumiblemente obtenidas con 5 secciones ‘peaking’). La imagen es el resultado de filtrar ruido blanco por el vocal filter con un alto Q, así que en esencia representa la envolvente espectral.

- A 800 1100 3000 4000 5000
- E 350 1200 2100 3000 4000
- I 270 2100 3000 4000 5000
- O 350 900 2800 3900 5000
- U 310 1100 2300 3700 5000

Pablo no puede callar cuando se habla de tecnologías audio/música. Doctor en teleco. Ha creado diversos dispositivos hard y soft y realizado programaciones para músicos y audiovisuales. Toca ocasionalmente en grupo por Madrid (teclados, claro).