Los sistemas de convolución: aspectos prácticos
Ya sea en hardware como el DRE S777 de Sony o en plugin como Altiverb, abundan hoy los sistemas basados en convolución. Con precios comerciales que suelen andar por las decenas o cientos de euros, pero que alcanzan también los miles, no faltan versiones freeware como HybridReverb2.

Tras haber digerido la presentación teórica del otro día, hoy vemos los límites de lo que sí y no puede emularse por convolución, consideraciones sobre el coste computacional y la latencia, productos disponibles, o la obtención de respuestas impulsivas (incluyendo webs de las que descargar algunas).
Convolución = ‘sampler de sistemas’ pero sólo lineales
“Consiga sonar como si estuviera en el cañón del Colorado o en el teatro de ópera de Milán”. “No importa qué mesa use conseguirá el sonido del previo marca X modelo Y”. “Convierta usted su micro en cualquiera de estos otros 20 modelos de alta gama”… La publicidad recalca que un sistema de convolución puede adquirir la personalidad de muchos otros sistemas. ¿Es la convolución el clonador universal, el todo-en-uno capaz de imitar cualquier espacio o equipo?
Tal como veíamos en el artículo anterior el patrón de rebotes/dispersión de un entorno o sistema (lo que llamábamos respuesta impulsiva) actúa como su ‘huella dactilar’ o casi sería mejor decir como su ‘DNA’. Puede usarse dispersar la señal de forma parecida a como lo hace el entorno o sistema real y con ello emula su comportamiento.
No es extraño por ello que se hable a veces de un ‘sampler de sistemas y entornos’, por analogía a los tradicionales samplers que permiten registrar sonidos. Y sí, ciertamente la convolución es una estrategia universal, sencilla y fiable para emular entornos acústicos y equipos audio diversos, pero sólo en lo referente a su comportamiento lineal.
Excelente para recrear con inusitado detalle los ambientes debidos a los ecos, reflexiones y reverberación que suceden en muchos espacios reales. Pero en cuanto a la emulación de equipos tipo micrófonos, previos, amplificadores, etc. aunque la convolución conseguirá imitar la coloración de tipo ‘filtrado’ que estos equipos imponen, deja fuera completamente las más que posibles saturaciones internas en donde se encierra una buena parte de la personalidad de estos equipos.
El paso por una cinta o equipo analógico (que a veces se aplica en grabaciones digitales para recuperar el calor analógico) no sólo imparte unas determinadas restricciones de ancho de banda, sino que tiene su sentido principalmente por la coloración que introduce como resultado de la saturación, que es inaccesible totalmente a ser imitada en forma de convolución.
Podremos imitar magníficamente las desviaciones de fase que introduce un ecualizador, o el paso por un previo analógico en cuanto a su singular respuesta en frecuencia, pero un sistema de convolución no tiene capacidad para recrear la pequeña distorsión que pueda aparecer en esosmismos equipos. No digamos ya en el caso de querer imitar un amplificador de guitarra, en el que la distorsión no es pequeña y es esencialísima parte de su acción. Imitar sólo la coloración lineal que imparte el conjunto formado por previo, etapa, altavoz y caja no conseguirá recrear con precisión el sonido distorsionado original.
Emulación de micros
Las no linealidades, a veces pequeñas y despreciables y otras veces no tanto, están en todos los sitios. Pensad en un micro. Da igual dinámico con su bobina o de tipo condensador. En el extremo de su excursión tanto la bobina como la placa del condensador vienen forzados, no están tan dispuestos a moverse con la misma comodidad que cuando están enfrentados a señal más pequeña. En definitiva distorsionan. Pretender que un sistema de convolución pueda recrear el sonido de un micro o de un previo ‘forzado’ a saturar, no tiene sentido. Sólo imitará la respuesta en frecuencia, lo que no está mal en sí, pero no es el todo. Imitación por convolución sí y magnífica, pero estrictamente circunscrita al comportamiento lineal.
Para obtener esa emulación lineal de un determinado micro habrá que hacer dos cosas: deshacer el efecto del micro que realmente hemos usado al grabar (para ‘neutralizarlo’, aplanando su respuesta), e imponer el efecto del micro deseado. Ambas cosas son factibles por convolución. Lo de neutralizar un micro correspondería a compensar sus desviaciones respecto a una respuesta plana, es decir, imponer la inversa a su respuesta en frecuencia (que no deja de ser otra respuesta en frecuencia para la que existe una respuesta impulsiva asociada). Pero será siempre la emulación del comportamiento lineal.
Fijaos por ejemplo en Antares MicMod EFX. Es un plug-in de ‘reemplazo’ de micrófonos: indicas qué micro has usado en la grabación y como cuál otro deseas que suene y dejas que haga su magia. Pero veis que cuenta con una simulación de válvula como forma de impartir una cierta saturación añadida. No está modelada realmente a partir del comportamiento no lineal de cada micrófono. Es un añadido para embellecer el sonido final, sin relación con los fenómenos no lineales en cada uno de los micros. Intenta aportar algo de esa parte que está ausente en una solución de convolución pura, pero sin realizar un modelado no lineal, siempre terriblemente difícil.

Ojo con las reverbs no naturales
Con las reverbs en espacios naturales no suele ser el caso que haya un efecto destacado de no linealidad. Por eso mismo la convolución es tan exitosa para este uso. El modelo lineal que subyace en la idea de la convolución es adecuado para la reverberación natural.
Pero en este concepto de ‘reverb natural’ no entrarían por ejemplo las unidades de muelles. Alguien comentaba tras el primer artículo que nunca estaba a gusto con las versiones digitales de las reverb de muelles, y que para las específicas ocasiones en las que se necesita ese tipo de reverb nada como la ‘electromecánica’ de una unidad de muelles de verdad.
Y tiene toda la razón. Es un ejemplo de un sistema que lleva de forma inherente no linealidades importantes, y que ilustra como a veces algo tan simple como un muelle puede resistirse a la enorme potencia de cálculo que tenemos en el hardware digital y los ordenadores de hoy.
Es evidente (probadlo si aún tenéis por casa algún somier de muelles y no de lamas) que un muelle, al igual que una cuerda libre, resuena a muy distintas frecuencias según esté más o menos tenso. Cambia mucho su flexibilidad y su patrón de resonancias en función de la tensión o estiramiento a que esté sometido. Cuando está en reposo tiene menor tensión y más dispuesto a vibrar en simpatía con lo que le llegue, pero cuando entra en movimiento está ‘estirándose’ y por tanto al mismo tiempo haciéndose más ‘duro’, menos abierto a vibrar. Pero la propia presencia de señal modifica su tensión y por tanto su respuesta. La definición misma de un sistema no lineal: el sistema cambia su comportamiento en función de cómo sea la señal que recibe.
Fijaos de hecho que en cualquier unidad reverb por muelles hay un control de tipo ‘drive’ que permite forzar el uso de la unidad en unos niveles de señal en los que sea claramente no lineal (ejemplo ). El uso que se hace de ese tipo de reverb es proclive a forzar la distorsión y aprovecharla creativamente, demasiado para una reverb convolutiva pura.
En definitiva, la convolución puede ser una herramienta excelente para recrear el carácter de sistemas lineales pero no pidáis peras al olmo. Cuando veáis que a una emulación convolutiva de un micro, de una reverb de muelles, de un previo, de un EQ… le falta carácter respecto a aquello que queríamos imitar: añadid algo de saturación o distorsión suave.
Imitación sí, pero foto fija
Aún hay más. Una respuesta impulsiva sólo representa una configuración fija del sistema estudiado. Pensando por ejemplo en imitar la respuesta de un micrófono, una respuesta impulsiva corresponde a una distancia y ángulo determinados entre la fuente y el micrófono. Sin embargo un cantante o instrumentista experimentado aprovecha su movimiento en relación al micro para variar el sonido resultante. Esas ‘variaciones’ no son posibles en un sistema basado en convolución, en el que por definición se aplica una respuesta impulsiva fija.
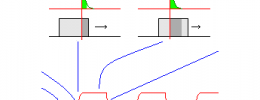
Pensad en algo tan sencillo conceptualmente como un filtro de reducción de ruido o si os gusta más como ejemplo un auto-wha. Ambos modifican su frecuencia de corte, más abierta para señales fuertes, más cerrada para señales débiles. Eso es nuevamente inasequible a ser imitado por convolución. Son sistemas que la convolución no puede alcanzar a imitar, porque son variantes en el tiempo. La respuesta impulsiva que puedo tener registrada corresponderá a una determinada frecuencia de corte. Alguno diréis: OK, puedo registrar la respuesta impulsiva para el filtro abierto y para el filtro cerrado y promediar ambas. Lo siento, no funciona. Mezclar al 50% las respuestas impulsivas lo que hace es combinar al 50% las respuestas en frecuencia y eso no lleva el punto de corte a la mitad, sino que crea una especie de ‘shelving’, porque equivale a poner los dos filtros (abierto y cerrado) en paralelo:
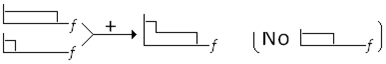
Siguiente idea que podéis plantear: OK, puedo registrar varias respuestas impulsivas e ir cambiando de una a otra… Pero se notarán los saltos, no será una transición fluida. Volveréis a contestar: en ese caso monto dos unidades de convolución para poder hacer que las transiciones de una a otra respuesta impulsiva estén sujetas a fundido. Y siento deciros que tampoco vale. No es lo mismo una variación continua que el fundido de variaciones a saltos. La diferencia es la misma que realizar un glissando, con una variación gradual, o ir recorriendo varias afinaciones de forma escalonada (pese a que se intente maquillar con los fundidos). No son acciones equivalentes y las diferencias pueden resultar demasiado burdas y obvias.

Yo suelo hacer la analogía con el mundo de la imagen: no tiene nada que ver un verdadero morphing que transforma la cara de una persona en la de otra estirando y desplazando sus cejas, nariz, etc., que el fundido de las fotos de la primera y la segunda que es una mera superposición de las dos caras durante la transición.
Sin ir a cosas tan extremas como lo del filtro de eliminación de ruido o lo del wha, hay que tener claro que convolución implica respuesta fija, comportamiento sin cambios, sin movimiento. No podemos modelar por convolución un flanger o un chorus por más que nos parezca que se trata de sistemas basados en un retardo / filtrado. Y no podemos porque en ellos por esencia ese retardo es móvil, cambiante.
Modelos por convolución, sin automatización
Relacionado con lo anterior. No podéis pensar en automatizar una emulación por convolución. Si queréis imitar un ecualizador en una posición fija de sus controles, perfecto. Obtenéis y aplicáis su respuesta impulsiva y hecho. Pero si se pretende imitar el que los controles del sistema imitado varíen sobre la marcha, la respuesta es no. La convolución no lo soporta.
Claro que hay plugins por convolución que permiten automatizar algunos de sus controles. Podréis automatizar, por ejemplo, la mezcla seco/mojado en una reverb por convolución, porque se trata de un parámetro que no es propiamente del motor de convolución. Sin embargo cualquier aspecto que se refiera esencialmente a cambios en el objeto emulado y su respuesta no puede soportarse.
Por convolución, si contáis con suficientes respuestas impulsivas para ‘situaros’ en distintos puntos del escenario de un teatro, podréis dedicaros a situar cada instrumento de la mezcla en una de esas posiciones, obteniendo una imagen estéreo espectacular y una sensación de espacio hiperrealista y congruente con esa particular sala. Pero olvidaros de conseguir imitar el que un instrumentista se esté moviendo por el escenario. Salvo que queráis que se mueva ‘a saltos’ claro. El ‘movimiento’ auditivo y la convolución me temo que no se llevan muy bien. Los efectos de tipo movimientos 3D en audio (RSS y semejantes) no pueden realizarse por esta vía.
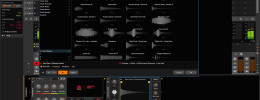
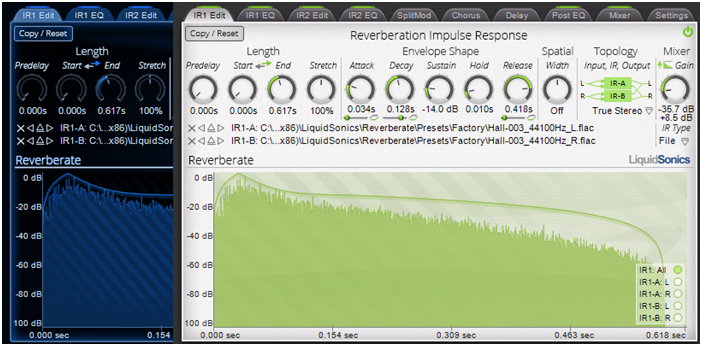
Los parámetros controlables que ofrece una reverb por convolución son muchos menos que los que estamos acostumbrados a ver en una reverb algorítmica. Pensad por ejemplo en la difusión y densidad de rebotes: está ‘grabada’, no está ‘generada’ algorítmicamente, y como resultado no puede alterarse.
Sí podéis jugar a dar más brillo o menos (los clásicos HF y LF damp) o en general a ecualizar la reverb. Sí podréis hacerla más corta porque se puede modificar la respuesta impulsiva atenuándola con una rampa decreciente para acortarla. Podréis también aplicar el impulso invertido para una reverb ‘reverse’. Pero poco más. Podéis ver esa ‘escasez’ de parámetros en esta figura.
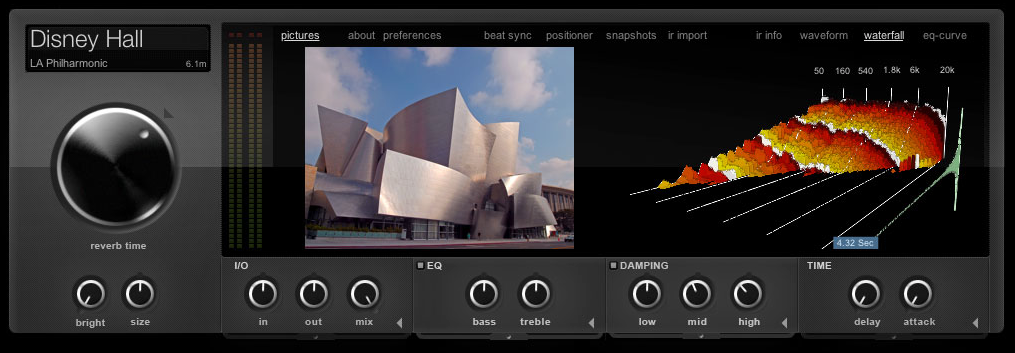
En algunas ocasiones tenéis control para gobernar con una cierta autonomía los primeros milisegundos de reverb (las primeras reflexiones) y el resto de la respuesta impulsiva, quizá incluso gobernando el ‘predelay’ de cada una de esas dos partes. En esos casos se trata nuevamente de transformaciones simples de la respuesta impulsiva: se trocea para separar el primer fragmento y la cola y se permite su manipulación separada. Pero olvidaros de una actuación más ‘íntima’ sobre la calidad de la reverb, como la referida del control de difusión o densidad que son sin embargo parámetros cotidianos en otras reverbs digitales.
El coste de calcular la convolución
He querido manifestar primero esas otras limitaciones de los sistemas convolutivos, porque son menos oídas. Pero no podemos dejar de mencionar la que siempre se cita: A cambio de su universalidad, tiene el precio de una computación que puede ser ingente y devora el uso de la CPU. En la entrega anterior veíamos la arquitectura interior de un plug-in de convolución, cómo se calcula eso que llamamos convolución. Pensando en esa figura podéis entender mejor lo que significa en términos de cómputo.
Supongamos que deseamos imitar una reverb cortita, de un segundo de cola. Bien modesta ¿verdad? No es un ‘hall’ ni un ‘canyon’, desde luego. Pero para poder tener registradala respuesta impulsiva a un frecuencia de muestreo de 44100 Hz necesitamos 44100 muestras. Y, ahora viene lo gordo, al aplicar ese patrón de rebotes, para cada muestra de la señal de entrada necesitamos realizar 44100 productos y sumas. Como hay 44100 muestras por segundo, resulta la friolera de un total casi dos mil millones de multiplicaciones y otras tantas sumas por segundo. A las que hay que sumar los accesos a memoria, ajustes de punteros,… Es más, necesitaremos operaciones en coma flotante que consumen más tiempo y energía (porque 2000 millones de valores sumados en coma fija desbordan seguro) o bien más operaciones para ir compensando los problemas de la coma fija.
No sigo. Pero lo que está claro es que la estrategia de la convolución demanda mucha capacidad de cómputo.Es cierto que en muchos procesadores (desde luego en cualquiera de tipo DSP, pero también cada vez más en procesadores ‘normales’ por la importancia que tiene a día de hoy toda la cuestión multimedia) existen precisamente elementos dedicados para resolver este tipo de cálculos: doble bus de datos, modos de direccionamiento peculiares, unidad MAC -multiplicación y acumulación en un único ciclo-, etc. Pero con todo, el coste computacional sigue siendo mayúsculo.
¿CPU caliente? Congela tu convolución
Si vuestro ordenador ya lo pasa mal para tener abiertas algunas reverberaciones algorítmicas dentro de un proyecto, mejor no intentéis reemplazarlas por reverbs de convolución… salvo que lo hagáis fuera de tiempo real. Es decir, dejando precalculada (fuera de tiempo de mezcla) la aplicación de esa reverb por convolución. Haciendo un ‘freeze’ pista a pista de esos efectos tan computacionalmente costosos.
No es ninguna idea nueva: siempre que el indicador de CPU se aproxima al 100% ha llegado el momento de congelar efectos y dejarlos grabados. Pero con los sistemas de convolución os podréis encontrar haciéndolo más que de costumbre.
¿No hay ninguna otra alternativa posible para reducir el cómputo? Si.
Reduciendo el cómputo
Para reducir el cómputo en lugar de realizar las operaciones en el dominio del tiempo (esos 2000 millones de productos y sumas) se prefiere trabajar en el dominio de la frecuencia. Esa suma de productos temporal corresponde en el dominio de la frecuencia a multiplicar el espectro de la señal por el ‘espectro’ de la respuesta impulsiva (que deberíamos mejor llamar ‘respuesta en frecuencia’ antes que ‘espectro’).
No es tanta panacea: hay que calcular la transformada de Fourier de la respuesta impulsiva y de la señal. La primera puede estar precalculada, no hay problema (el impulso es fijo), pero la segunda no queda más narices que irla calculando sobre la marcha. Calcular la transformada añade sus propias (y no pocas) sumas de productos. Pero al final con el uso de la FFT compensa y puede reducirse el cómputo unos cuantos centenares de veces (la cifra exacta depende de varios factores como la duración del impulso).
No es una entelequia. La propia Sony SRE S777 lo hace. Calcula la convolución en el dominio de la frecuencia para hacer factible realizarla en tiempo real a pesar de la larga duración de los impulsos que puede aplicar. Y estoy tentado de deciros que casi cualquier equipo o soft que soporte duraciones de impulsos amplias (no sólo para las primeras reflexiones o milisegundos) también aborda el cálculo saltando al dominio de la frecuencia.

Esos 2000 millones de productos y 2000 millones de sumas eran para entrada y salida mono, a ‘sólo’ 44100 y con una cola corta. Pensad en cualquier otra configuración y recordad que el crecimiento es cuadrático: si dobláis la frecuencia de muestreo, cuadriplicáis la demanda de cómputo. Si en lugar de un segundo el impulso en la sala dura dos, de nuevo cuadriplicáis cómputo. En definitiva, la sencilla implementación temporal no resulta factible salvo para el fragmento más inicial de la reverberación. Si queremos respetar el impulso original en su integridad y no sustituir su cola con una reverb generada de forma algorítmica, no queda más posibilidad que acudir al dominio de la frecuencia.
La aparición de latencia
Pero… (no podía faltar algún pero) para calcular el espectro de la señal tenemos que ir considerando trozos de la señal, fragmentos. No podemos ir calculando el ‘espectro’ de cada muestra. El espectro sólo tiene sentido para fragmentos de señal. Y en definitiva eso implica que no podemos obtener la salida de forma ‘instantánea’. Tiene que haber algún tipo de buffering que acumule muestras hasta formar el fragmento con el que realizar el cálculo. Y buffering siempre implica latencia (p.ej. unos 6 o 7 ms si no recuerdo mal en el SRE S777). Cuando la señal con latencia se combine con la original (o con la diafonía que se haya colado hacia otras pistas por los micros, etc.) podemos esperar la aparición de cancelaciones de fase y demás florituras. No todo el mundo está feliz tras gastarse unos cuantos miles de euros en una reverb para luego ver que junto con ella te han regalado un flanger sin botón de on/off. Ciertamente hay formas de sobrevivir con compensación de latencia, realineando pistas, etc. pero son soluciones para situaciones ‘no en vivo’, claramente.
Es más cualquier tratamiento ‘por bloques’ como el que se necesita para realizar la convolución operando en el dominio de la frecuencia exige trocear la señal, y conseguir que esa ‘granularización’ no se evidencie en el resultado exige hacer las cosas con mucho cuidado, introducir enventanado y solapamiento entre los fragmentos, u otras soluciones. Cosas que de nuevo pueden subir la computación e introducir algunos efectos de cancelaciones.
¿Son todos los sistemas de convolución iguales?
Así que tenemos la implementación ‘a las bravas’ en el dominio del tiempo con una salvajada de operaciones pero que está libre de latencia, o la implementación más asequible computacionalmente de tipo frecuencial, pero acompañada de algunos inconvenientes. La tentación de ir por la vía de calcular todo en el tiempo y evitar así latencias y granularización no es la solución, es inabordable computacionalmente.
Y aquí es donde podéis encontrar diferencias audibles entre lo que, en teoría deberían ser procesos equivalentes (al fin y al cabo la convolución con un mismo impulso debería dar siempre un mismo resultado ¿no?).. En sistemas de convolución de alta gama podéis esperar que se hayan estrujado la cabeza lo suficiente para obtener una solución en el dominio de la frecuencia con un cómputo no imposible pero libre de los artefactos de ‘granularización’, con un solapamiento controlado y bien alineado, sin cancelaciones notables.
Eso sí siempre existirá latencia si el cálculo es frecuencial, por muy alta gama que sea el equipo. Quizá suficiente dinero pueda comprar la voluntad cualquier persona, pero con la física los euros no valen.
En definitiva, no todos los sistemas de convolución (incluso usando los mismos impulsos) van a sonar igual ni tener las mismas prestaciones/comportamiento. Algunos serán más consumidores de CPU, otros menos, algunos tendrán mayor latencia que otros…
Las diferencias audibles son casi siempre pequeñas, pero inciden en cosas como un mejor/peor reflejo de la imagen estéreo, una pequeña dosis de presencia extra de reverb,…Para una comparativa sobre varios sistemas de convolución podéis ver http://re-sounding.com/2011/06/15/ir-plugin-comparisions, en donde tenéis un mismo impulso aplicado a una misma señal a través de distintos paquetes de soft.
Los que tengáis un perfil marcadamente técnico/matemático volcado hacia DSP, podéis leer este artículo sobre las diferentes formas en las que puede abordarse el cálculo de la convolución (en el tiempo, en frecuencia mediante overlap-addu overlap-save, etc.): http://www.music.miami.edu/programs/mue/Research/jvandekieft/jvchapter2.htm
Algunos productos
Para que nadie quede sin probar esto de la convolución, en los viernes freeware de hispasonic recientemente apareció mencionado Nebula3 free disponible para Mac y Win, pero es una versión cerrada con unos cuantos modelos ‘prefijados’. Más abierta es HybridReverb2 que podéis descargar por ejemplo en http://www.myvst.com/vst-effects/hybridreverb2-free.
Por la vía del hardware los ejemplos clásicos son la Sony SER S777 y la Yamaha REV1, ambos con calidad y precios estratosféricos para la mayoría de los mortales. Pero la vía hardware no parece un mercado prolífico.

Todo lo contrario a las convoluciones vía soft / plugin, con infinidad de productos. Entre otros: Altiverb (Audioease), Reverberate (Liquidsonics), PristineSpace (Voxengo), IR-1 (Waves), MMultibandConvolution (Melda) o SIR2 (Knufinke).
De hecho ha llegado a convertirse en un ‘imprescindible’ hasta el punto de que muchas DAWs incorporan sistemas de convolución: REVerence en CubaseSteinberg, SpaceDesigner en Logic, TL Space en ProTools.
Muchos de ellos a día de hoy soportan la convolución multicanal (para recrear la reverberación natural en sistemas 5.1 y semejantes).
Hay casos en los que se venden con el atractivo argumento de la convolución reverbs que en realidad son híbridas y que combinan una estrategia de convolución para las primeras reflexiones y una generación de cola algorítmica algorítmica. Un caso evidente es Audioreverb para iOS de VirSyn,no cabría esperar de un dispositivo tipo iPad el que resistiera las exigentes necesidades de una convolución más extensa.
Dentro de otros tipos de productos también encontramos uso de la convolución nuevamente híbrida las más de las veces. Por ejemplo el uso de convolución en las reverbs de sintes como DrumLab o Halion y tantísimos otros, que permiten cargar una respuesta impulsiva, aunque corta, para al menos poder replicar las primeras reflexiones, que es bien cierto son las más significativas en nivel y perceptualmente.
Limitar la parte convolutiva a los muy primeros milisegundos reduce muchísimo la demanda computacional y permite un implementación estrictamente en el dominio del tiempo, ajena a latencias. Pero recrear el resto de la cola por medios algorítmicos, hace que se pierda en esas colas la naturalidad. Como con cualquier reverb algorítmica, hay un exceso de ‘redundancia’, de ‘autosemejanza’ o repetición en la cola, una falta de verdadero ‘caos’ y aleatoriedad en la secuencia de rebotes. Y eso de alguna forma nuestra percepción lo detecta como una reverb comparativamente más pobre y que cuesta más llegar a asentar en la mezcla.
Generar respuestas impulsivas
Obtener las respuestas impulsivas no es una labor para principiantes (salvo en el caso trivial de sistemas digitales en los que el impulso sí existe y es usable). Así que dependemos en buena medida de la colección de respuestas disponibles. Pasa a ser casi más importante que el propio software (muy simple de diseñar, lo que no quita que conlleve un coste de CPU enorme).El precio de Altiverb por ejemplo no nace tanto del desarrollo del software de convolución como de la cantidad de trabajo realizado para generar y documentar una extensísima colección de respuestas, que están clasificadas en una base de datos que facilita su uso.
Típicamente las respuestas impulsivas que acompañan a los sistemas de convolución se distribuyen como ficheros de audio (a menudo en formato wav). No se trata de ficheros pensados para ser oídos, sino para ser aplicados mediante convolución a los verdaderos ficheros audio. Aún así, como en el caso del lutier que golpea la caja del instrumento, su escucha da buenas pistas sobre su carácter.
Y esas colecciones de respuestas impulsivas pueden ser generadas por cualquiera (no sólo por el fabricante del software). No es extraño que haya terceras partes desarrollando colecciones de impulsos que se comercializan como librerías de impulsos para los sistemas de convolución más exitosos. Si tiene el conocimiento y las herramientas necesarias para la obtención de respuestas impulsivas, esas terceras partes pueden crearlas y venderlas.
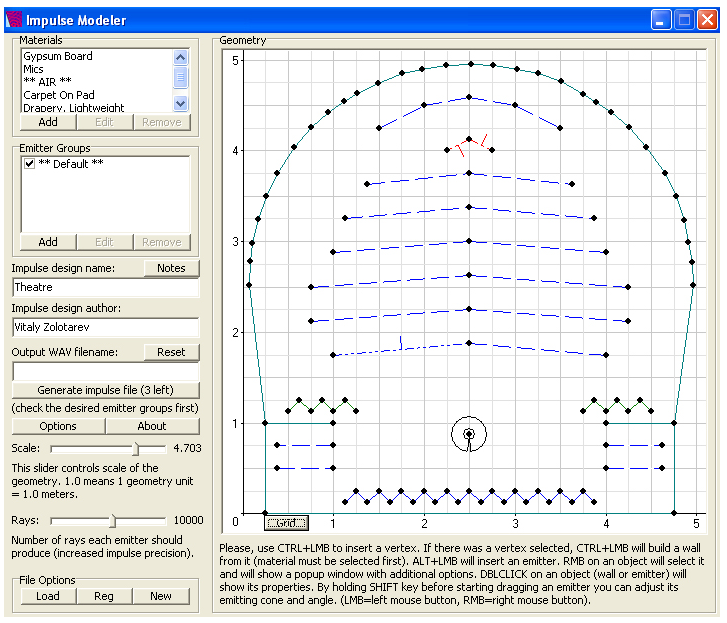
Una forma de generar respuestas impulsivas es usar programas que permiten diseñar una sala (sus paredes, materiales, etc.), ubicar una fuente y unas escuchas y dejar que se sintetice artificialmente el conjunto de ecos. No siempre sonarán íntegramente naturales, pero en ocasiones puede resultar interesante. Una de tales herramientas es Impulse Modeler de Voxengo.
La otra forma de obtenerlas es ‘sampleando’ un entorno real. Ya lo mencionábamos en la entrega anterior. Muchos de los productos comerciales de convolución cuentan con rutinas para generar señales de prueba, registrar las respuestas y calcular automáticamente la respuesta impulsiva. Generalmente usan un barrido de tono. Pese a que estén disponibles esas facilidades, lo cierto es que llegar a buenos resultados no es tan fácil. Hay que contar con buenos equipos de reproducción y grabación y asegurar que el entorno esté en silencio suficiente para obtener un registro adecuado.
Tenéis aquí un ejemplo de obtención de la respuesta de una iglesia con Altiverb, que os explico brevemente para los que no manejéis el inglés.
Esencialmente Altiverb ofrece un juego de señales de prueba que son barridos entre 5Hz y 22KHz de distintas duraciones (a efectos de poder obtener la reverb de salas con mayor o menor tiempo de reverberación). El barrido va precedido/sucedido de silencio. Eso permite estimar el nivel espectral de ruido y usarlo para mejorar la calidad de la medición, y también permite abrigar la cola de reverb tras el barrido. Todo el conjunto silencio/barrido/silencio va enmarcado entre sendos ‘pitidos’ de principio y fin y que permiten a Altiverb automatizar la comparación entre la señal de prueba y la registrada en la sala. Esa señal hay que reproducirla con un equipo de buena calidad en la sala y habrá que grabar lo que se escucha en el punto deseado de esa sala. Comparando el barrido original (limpio) y el registrado en la sala (reverberante) puede obtenerse una respuesta impulsiva. Para conseguir una medición con una buena relación señal ruido, hay que reproducir el barrido a alto nivel, sin llegar a saturar.
No es una tarea difícil, pero sí exige un cierto rigor y equipo. Siendo realistas ni tú ni yo vamos a obtener los permisos para dedicar unas jornadas dentro del Carnegie Hall para estas cuestiones, ni tampoco el que ofrezcamos la respuesta de nuestro salón o nuestro cuarto de baño va a resultar atractivo para los posibles compradores. Así que lo de crear librerías comerciales lo dejaremos para otros. Aun así, obtener tus propias respuestas no es algo para descartar. Si tenemos un espacio donde algo suena generalmente bien o que nos interesa reutilizar más tarde, podemos hacernos con su respuesta impulsiva. Un ejemplo de clarísima utilidad es el que sigue.
Utilidad para el doblaje
El uso de reverbs de convolución en vídeo, cuando sabemos que el sonido directo va a ser reemplazado mediante doblaje, es una alternativa muy interesante. Una forma no complicada de asegurar una consonancia adecuada entre el espacio que se ve en la imagen y el espacio que se escucha es capturar respuestas impulsivas de ese espacio (antes de que lleguen los actores y tramoyistas, claro, para asegurar silencio). Si tu software sólo realiza la convolución pero no cuenta con un sistema de ‘captura’ de respuestas impulsivas, puedes usar Deconvolver de Voxengo.
Podremos así contar con ellas como recurso en tiempo de postproducción y mezcla para aplicarlas y recuperar esas reflexiones naturales. Pueden ser una forma ágil de realizar la producción, sin descartar complementarla con otros tipos de reverb (algorítmicas) especialmente cuando lo que necesitemos sea generar sensaciones ‘de movimiento’. Pero como siempre, cuando de cualquier cosa nos importa el movimiento, no nos importa tanto su precisión. Un sistema tipo RSS puede generarnos la ilusión de una trayectoria acústica, y lo que dominará la escucha será el disfrute de esa trayectoria haciendo irrelevante el detalle íntimo de la propia reverberación en sí. Pero sin embargo en una situación más estática, la naturalidad de una reverb que emula el espacio real, con sus dimensiones y formas, sus materiales, etc. puede aportar una agilidad impagable para llegar al resultado final.
Disponer de las respuestas del espacio donde se rodó la imagen es una forma de agilizar la postproducción. No necesitaremos probar y probar hasta dar con una reverb que encaje. Sencillamente aplicar la reverb natural de ese espacio ‘sampleada’ en su respuesta impulsiva.
Una situación análoga se da cuando tenemos un solista acompañado por orquesta. A menudo pondremos microfonía cercana al solista para poder recoger un sonido lo más aislado posible, sin tanta mancha de los demás elementos que comparten el escenario. Pero al estar tan cercano la sensación es pobre: se pierde la riqueza del efecto sala. Y un micro de ambiente, volverá a darnos un exceso de diafonía.
Si contamos con la respuesta impulsiva, podremos aportar ese efecto sala a la señal de ese micro tan cercano y tendremos una posibilidad más para jugar y decidir el mejor tratamiento en tiempo de producción/mezcla.
Diferentes puntos de escucha / fuente
La respuesta impulsiva grabada en un auditorio en la fila 7 de butacas o en la fila 4 de entresuelo (no digamos ya en el gallinero) no tiene nada que ver. O equivalentemente, si me sitúo en la fila 7, el patrón de reflexiones que me llega del violín concertino situado en primer plano de la izquierda del escenario no tiene nada que ver con el que llega de la flauta travesera más atrás y a la derecha. Por ello, no existe una única ‘respuesta impulsiva’ de una sala.
Tiene especial importancia en casos como la librería Vienna Suite. Tratándose de una librería orquestal, ofrece el MIR-Pro (Multiple Impulse Response) y varias librerías de impulsos correspondientes a algunos auditorios selectos. MIR-Pro aprovecha múltiples respuestas impulsivas de cada sala presentes en esas librerías y correspondientes a diferentes situaciones de la fuente sonora. Una mejora que permite separar y definir mejor cada instrumento en la mezcla situando cada instrumento en su lugar. Lógicamente la computación se dispara salvajemente al aplicar convolución con impulsos diferentes a cada pista, instrumento o sección y no una única respuesta compartida con envío desde cada pista.
Ejemplos de colecciones de impulsos
A estas alturas debería estar claro que un sistema de convolución no es nada si no tenemos junto con él una colección de impulsos adecuada. Así que no podíamos cerrar página sin ofrecer algún recurso gratuito de este tipo.
No sólo los espacios naturales y grandes auditorios ‘sampleados’, en librerías de impulsos de pago también suelen incluirse respuestas extraídas de equipos de prestigio. Si pensamos en las reverbs digitales, muchas de ellas usan algoritmos fijos y el patrón de ecos que generan es constante, ningún problema por tanto para una emulación por convolución. Pero en algunas (Lexicon viene a la cabeza) se potencia una mayor riqueza de la reverberación haciendo que el patrón de reflexiones esté sometido a variación. Los enlaces con impulsos de algunas reverb clásicas os permitirán juzgar por vosotros mismos el resultado de samplear estas unidades de reverb que son ‘variantes’. Dando por hecho que la duración de la respuesta impulsiva sea ‘completa’, pasan por una magnífica reconstrucción del carácter de esos equipos. Esa duración retiene suficiente variación como para aportar esa riqueza.
El hispasónico Fernando Monreal en respuestas a un hilo sobre Altiverb aportó tres enlaces que aquí repito. Toda una ocasión para tener en nuestra casa las reverb de algunos productos de alta gama.
- En una librería de 84 MB están disponibles los impulsoso de un montón de presets de la Lexicon 480L
- Si os apetece saber cómo sonaría una Bricasti M7 en vuestro proyecto podéis mirar aquí
- Otro lote de impulsos interesante es este
Añado otros cuantos que seguro harán soñar a más de uno:
- Impulsos generados a partir de Eventide H3000
- Impulsos generados a partir de TC Electronics M5000
Y finalmente aquí podéis encontrar otras varias colecciones de impulsos gratuitos (id al final de esa página para ver los enlaces).
Hay otras muchas fuentes, pero con esas ya hay para entretenerse un buen rato. Usadlas con cualquier soft que tengáis de convolución o descargaros algún plugin gratuito, pero no será mi culpa si este verano no os ponéis morenos.

Pablo no puede callar cuando se habla de tecnologías audio/música. Doctor en teleco. Ha creado diversos dispositivos hard y soft y realizado programaciones para músicos y audiovisuales. Toca ocasionalmente en grupo por Madrid (teclados, claro).