El futuro de la síntesis de canto se oye en la UPF

El MTG (Music Technology Group) de la UPF (Univ. Pompeu Fabra) es responsable de la tecnología que subyace en el conocido software Yamaha Vocaloid para creación de líneas de voz cantada. Dos de sus miembros (Merlijn Blaauw y Jordi Bonada) presentan un artículo de investigación con resultados y ejemplos de una nueva estrategia. Basada en redes neuronales para el entrenamiento de los modelos y síntesis de voz (vocoders) para la creación de la señal, dicen igualar la calidad y naturalidad de los sistemas más habituales basados en la concatenación de fragmentos grabados, pero con recorrido para ayudar a superar algunos de los problemas que perviven en estos.

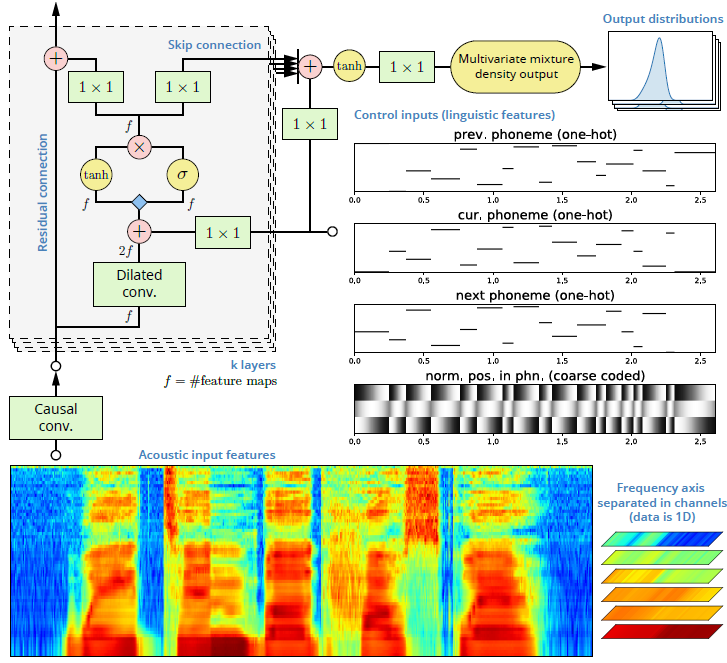
Son mayoría los sistemas de generación de líneas de canto basados en el uso de segmentos breves de voz grabada que se concatenan y modifican, y obtienen resultados razonables en términos de calidad de audio y de naturalidad del sonido aunque sigan siendo reconocibles como de origen 'máquina'. La vía que ofrece el nuevo estudio es la de usar sistemas de síntesis de voz (vocoders) para apovechar su mayor flexibilidad frente a la rigidez del material base muestreado, y combinarlos con sistemas de entrenamiento basados en redes neuronales para que el propio sistema aprenda del canto real y pueda reconstruir sus características en la versión sintetizada.
Desde luego, en los ejemplos sorprende el grado de calidad al que se llega con esta vía estrictamente 'sintetizada' capaz efectivamente de competir ya en cuanto a naturalidad con la basada en segmentos muestreados.
Los sistemas de síntesis tienen ventajas inherentes, como la posibilidad de separar la evolución del timbre y la evolución del tono. Pueden ayudar a esquivar el problema de los saltos y discontinuidades que la vía de la concatenación de segmentos acaba manifestando, al menos en algunas situaciones críticas. Situaciones críticas que el canto expone frecuentemente, debido a sus grandes excursiones de tono, a la importancia del timbre y sus matices, y en general a cómo se produce y cómo se escucha el canto.
No sabemos cómo acabarán estos desarrollos saliendo del laboratorio y llegando a estar presentes en alguna forma de software para usuarios finales, pero con la trayectoria probada del MTG en este campo, sólo puede ser cuestión de tiempo.
De momento podemos oír el avanzado estado actual de sus 'criaturas' en esta página desde la que ofrecen varios ejemplos audio tanto de canto en inglés como en castellano, con y sin fondo musical acompañando a varios temas populares.

Pablo no puede callar cuando se habla de tecnologías audio/música. Doctor en teleco. Ha creado diversos dispositivos hard y soft y realizado programaciones para músicos y audiovisuales. Toca ocasionalmente en grupo por Madrid (teclados, claro).